1
2
3
4





谷歌DeepMind团队的阿尔法折叠2 (AlphaFold2)使用最新的人工智能算法对蛋白质结构实现了接近实验精度的精准预测。这一成果被美国《科学》杂志评为2020年十大科学突破之一。复旦大学复杂体系多尺度研究院教授马剑鹏团队与上海人工智能实验室合作,近日以《OPUS-Rota4: 一个基于梯度和深度学习的蛋白质侧链建模框架》(“OPUS-Rota4: a gradient-based protein side-chain modeling framework assisted by deep learning-based predictors”)为题在《生物信息学简报》(Briefings in Bioinformatics)上发表论文,展示了蛋白质侧链预测算法(OPUS-Rota4 算法),其精度显著超越了谷歌团队的阿尔法折叠算法。 在目前阿尔法折叠算法开源的情况下,复旦团队的算法可以为任何蛋白质结构预测工作提供比阿尔法折叠更准确的侧链模型,从而为蛋白质结构研究,尤其是基于蛋白结构的新药设计工作提供了利器。
用人工智能系统预测蛋白质结构,有什么价值?马剑鹏介绍,蛋白质由一系列氨基酸折叠而成,具有稳定的三维结构。如果掌握了各种蛋白质的精确三维结构,科学家在生命科学研究中就好比有了导航地图。然而,用冷冻电镜等实验设备测定蛋白质结构的难度很大,而且经济成本、时间成本很高。如果人工智能系统可以快速、精准地预测蛋白质结构,新药研发等工作的效率将大幅提高,成本也会随之降低。
蛋白质三维结构由主链和侧链共同搭建而成,人工智能系统预测蛋白质结构的通常步骤,是先为蛋白质主链建模,再根据主链的构象为侧链建模。自然界中的蛋白质含有20种氨基酸,它们的主链几乎完全相同,而侧链差异很大。由于药物分子与人体蛋白质结合的位点绝大多数在氨基酸侧链上,人工智能系统对侧链的精准预测对新药研发具有重要价值。这种精准预测能力还可用于解释基因点突变、基因小片段突变的机制,为遗传性疾病研究和治疗提供宝贵思路。
精准的蛋白质侧链建模对蛋白质折叠和蛋白质设计至关重要。近年来的研究中,研究人员开发的侧链建模算法大多基于抽样,如SCWRL4、OPUS-Rota3等。其从离散的侧链二面角转子库中进行抽样,随后根据一系列能量函数进行优化,找到能够让能量最低的二面角转子即为最终结果。基于抽样的侧链建模算法优点是速度较快,但由于使用离散的转子并受限于能量函数的准确性,其整体侧链预测精度仍然有待提高。
OPUS-Rota4引入深度学习算法,使得蛋白质侧链建模精度得到了大幅提升。研究人员首先使用OPUS-RotaNN2结合多种不同的提取特征得到初始的侧链二面角预测结果,之后使用OPUS-RotaCM得到侧链原子接触图,最后使用其自主研发的建模框架OPUS-Fold2根据接触图对初始侧链二面角预测结果进行优化并输出最终结果。
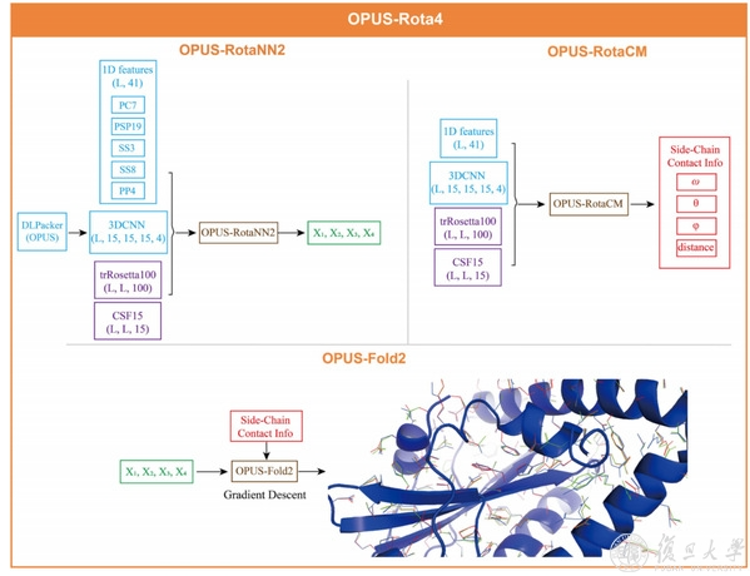
图为OPUS-Rota4整体框架
研究人员在三个天然构象测试集中进行了测试,其中CAEMO(60)包含60个测试蛋白,CASPFM(56)包含56个测试蛋白,CASP14(15)包含15个测试蛋白。其结果显示,在三个测试集中,OPUS-Rota4的结果均优于其它侧链建模算法。
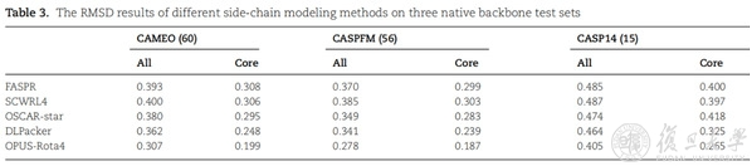
图为RMSD结果。数值越低说明越接近天然构象。All代表全部残基,Core代表中心残基。全部残基包含中心残基和表面残基。中心残基位于蛋白质内部,对其生物学功能更为重要。
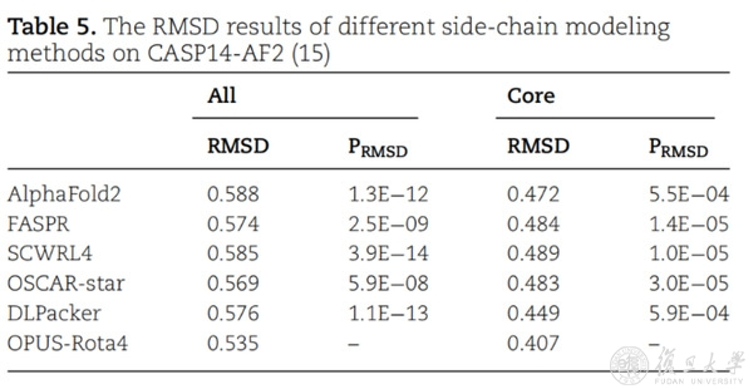
除了三个天然构象测试集外,研究人员还使用AlphaFold2得到了CASP14(15)中15个蛋白的预测结构,并根据预测主链结构对其侧链用不同方法进行重新建模。其结果显示,OPUS-Rota4的结果显著优于其它侧链建模方法,而且比AlphaFold2预测的侧链更接近天然构象。
研究人员展示了几个预测较为成功的结构。结果表明,OPUS-Rota4的侧链预测结果和天然构象基本接近,尤其是对于那些位于蛋白质内部的中心残基。
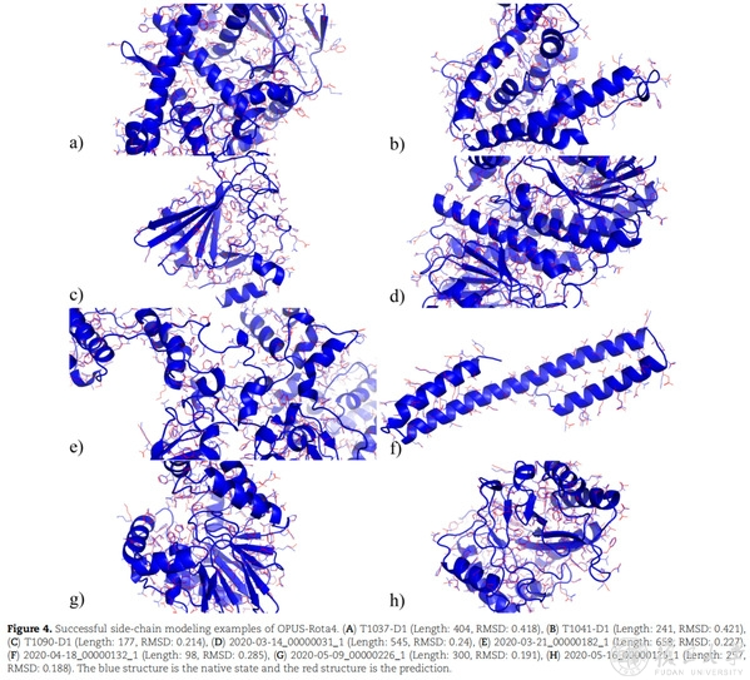
如图所示,蓝色为天然构象,红色为预测结果。
研究人员还对几个相对预测较差的结构进行了分析。研究人员认为,其预测较差的主要原因可能是这些结构中都存在较长的无序loop区域,该区域的氨基酸侧链结构自由度较高。
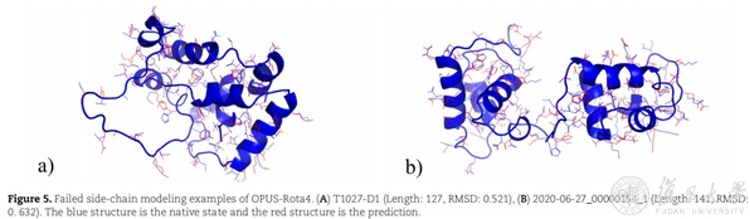
研究人员表示,将会对蛋白质侧链建模进行进一步研究,以期继续提升准确率,并将对侧链建模在实际问题中的应用进行探索。侧链预测的技术难度很大。马剑鹏打比方说:“基于高精度的自然主链构象来建侧链结构,就像在静止的船甲板上做金鸡独立,站稳很不容易。如果是基于计算机预测的非自然主链构象来建侧链结构,就像在摇晃的船甲板上做金鸡独立,难度更大。”
复旦大学复杂体系多尺度研究院青年副研究员徐罡为论文第一作者,复旦大学复杂体系多尺度研究院院长马剑鹏为通讯作者。





